Rodin Index Design: Difference between revisions
imported>Nicolas |
imported>Nicolas |
||
| Line 178: | Line 178: | ||
* dependencies between files | * dependencies between files | ||
Moreover,the index manager must also persist its state, that is the list of deltas not yet fully processed when the platform shuts down | Moreover,the index manager must also persist its state, that is | ||
* the list of deltas not yet fully processed when the platform shuts down | |||
* the indexer registry | |||
Upon startup, the delta list will be recovered and indexing resumed where it stopped. | |||
If the indexer registry changes (e.g. indexers added), a full indexing will be scheduled to update the index with the new indexer configuration. | |||
===Project save=== | ===Project save=== | ||
Revision as of 15:37, 3 March 2009
Purpose
The purpose of the Rodin index manager is to store in a uniform way the entities that are declared in the database together with their occurrences. This central repository of declarations and occurrences will allow for fast implementations of various refactoring mechanisms (such as renaming) and support for searching models or browsing them.
Specification
The name table
Firstly, the index manager needs to store declarations. We make the assumption that a declaration corresponds to one and only one element in the database.
For event-B, this assumption is true. For instance, a variable declaration is an IVariable element, an event declaration is an IEvent, etc.
However, the element handle doesn't carry directly the user-defined name for the element. This name is stored as an attribute of the element. Thus, one needs to access the element in the database to retrieve this name. We therefore want to cache this name in the index to prevent frequent accesses to the database that would hinder performance.
The user-defined name of a variable is stored in its identifier attribute, the name of an event in its label attribute.
So, the first table that the index manager needs to maintain is specified as
,
where 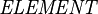 is the set of all element handles and
is the set of all element handles and 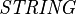 is the set of all character strings.
is the set of all character strings.
The occurrences table
Secondly, the index manager needs to maintain the relation between declarations and occurrences. This relation is specified as
,
where 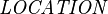 is the set of all locations in the database, a location being either an element, or an attribute of an element, or a substring of an attribute of an element. We also have the following function which relates a location to the element that contains the location
is the set of all locations in the database, a location being either an element, or an attribute of an element, or a substring of an attribute of an element. We also have the following function which relates a location to the element that contains the location
.
However, note that this relation is not maintained by the index manager; it is inherent to the definition of locations.
Populating the Index
Following the general principles of the Rodin core, the Rodin index manager is notation-agnostic. Therefore, it cannot populate the index by itself, but delegates this to plug-ins through an extension point. These contributions are called indexers.
Then, the question arises to define the granularity at which these indexers will be declared and work. Having an indexer declared and working on a whole project would be too coarse grain. Conversely, having an indexer declared and working at the granularity of internal elements would be too fine grain. So, it has been decided that indexers are declared for file elements, based on their type. In hindsight, we are taking here the same design decision we took for the event-B tools when defining the granularity of static checking and proof obligation generation.
Moreover, we want to keep the index at least as open as the Rodin database. So, we need to be prepared to accommodate several indexers working on the same file, as the elements contained in a file can be contributed by several plug-ins. In this case, the side question is in which order should these indexers be run. The solution chosen is that any indexer can declare that it should be run after another indexer. In other words, plug-ins can define a partial order among the indexers that will be enforced by the index manager.
Putting everything together, we obtain an extension point for contributing indexers with the following components:
- id: unique identifier of the indexer
- name: human-readable name of the indexer
- class: implementation of the indexer
- type: list of the file element types handled by the indexer
- after: list of the ids of the indexers that must be run before the indexer
Index Maintenance
Of course, the database will change when users edit their models. We therefore must define a policy for updating the index when the database is modified. Detecting database changes is easy, thanks to the deltas that are generated by the database manager upon modification.
The difficulty here is that there is no restriction on the occurrences of an element: an element can occur in the file where it is declared, but it can also occur in a completely different file.
For instance, in event-B, a constant can occur in the context where it is declared, but also in any context that extends (directly or indirectly) its declaring context.
So, in principle, each time a file changes, we have to re-index all files. This is clearly not acceptable from a performance point of view. In order to keep index updating efficient, we need to better organize the way file changes are propagated in the index. For this, we first need to gather additional information from indexers (like dependencies between files), then we have to enforce some restrictions on the indexes contributed by indexers, so that we can compute the consequences of a file change.
Dependencies
Firstly, we ask the indexers to provide the index manager with the list of files that a given file depends on. This is stored in the table with the following specification
,
where 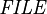 is the set of all files.
is the set of all files.
From this table, we can compute a total order on the files to index, also maintained by the index manager, thus avoiding repeated traversal of the dependence graph. If 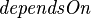 contains a cycle, it will be broken and all files will be processed nevertheless. In this case, dependencies will not be fully enforced and some data may be missing in the resulting index.
contains a cycle, it will be broken and all files will be processed nevertheless. In this case, dependencies will not be fully enforced and some data may be missing in the resulting index.
But having these dependencies is not precise enough, and can still lead to a lot of unnecessary indexing.
For instance, in event-B, if the user adds a theorem to a context on which all files of a project depend (e.g., the context seen by the top-level machine of this project), then we would have to re-index all the files of the project, although it will be useless, as the theorem is not visible to the other files.
Therefore, we also ask that the indexer reports the declarations that are exported (i.e., made visible) by a file to the files that depend on it. This information is stored in the table specified as
.
Restrictions
Then, to minimize re-indexing, we ask that indexers behave as good citizens and enforce some restrictions on the elements and locations that an indexer can contribute to the index.
To express these constraints, we need a new constant relation that gives the file in which an element is declared
.
This relation is a constant and is inherent to the database structure; it is not maintained by the index manager, only used by it.
Firstly, we ask that an indexer running on file 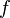 contributes names only for elements belonging to this file, i.e., these elements must belong to set
contributes names only for elements belonging to this file, i.e., these elements must belong to set
.
Secondly, the indexer must contribute only occurrences in file , that is the occurrences provided by an indexer must belong to the set
.
Thirdly, an indexer only contributes occurrences for elements declared in the file on which it is run or exported by a file on which this file depends directly, i.e., the elements for which an indexer contributes an occurrence must belong to the set
.
Finally, an indexer can only export elements for which it can contribute occurrences, as detailed in the previous point.
Updating algorithm
Given these restrictions, we need to update the index for a file only if
- either the file has changed,
- or the elements visible in the file have changed
since the last time it was indexed.
Formally, the last property means that the following set has changed
.
Concurrency
Indexing should disturb the user experience as little as possible. Therefore, indexing must take place in a separate thread. This is achieved by using the Job API of Eclipse. All indexing takes place in a low-priority job.
Concurrency problems might arise from several interactions:
- deltas are received asynchronously from the database
- the user should be able to cancel indexing if anything goes wrong
- indexers have to read files from the database while they are potentially being modified concurrently (editing)
- the index can be queried while it is concurrently updated following to a database change
Queuing deltas
The database delta mechanism requires that clients process change events quickly. Therefore, we cannot process database changes directly, but we rather queue them for later processing by the indexing thread. This is done through a blocking queue.
Also, another source of index updating needs is project state changes (create/delete, open/close, clean). Such changes are also enqueued for later processing.
Furthermore, blocking queues provide a thread-safe way to wait for deltas to arrive to the indexing thread, avoiding needless resource consumption with busy waiting.
Interactive indexing job
We want to give the user both a feedback on indexing activity, and a way to cancel it if needed. However, we do not wish to stop the whole index manager on a user cancel.
So the indexing system is split between the background Index Manager Job on the one hand, and an interactive Indexing Job on the other hand, that calls indexers. The first launches the second when files must be processed. The second is thus cancelable, but it does not imply stopping the whole indexing system.
Cancellation can be requested through a popup that appears when the Job is taking too much time to complete, or from the progress view. Received at Job level, cancellation is propagated towards indexers, which are required to check it regularly and stop as soon as possible.
Exclusive database access
When indexers are given a file to index, we must be sure that it is not being modified concurrently. The database provides a way to manage exclusive access to its data, through Job scheduling rules. The interactive indexing job has to first acquire this exclusive lock, potentially waiting for others to finish (the builder for instance), before calling indexers.
Handling queries
Index contents are perpetually evolving, as long as files get modified. Thus, the problem arises to ensure that the data is valid and up-to-date when responding to queries. We therefore provide clients with a way to wait until indexing is complete.
To have a correct state, the following must hold:
- the delta queue is empty
- no file is being indexed
This is achieved by putting a latch on the delta queue. The latch maintains a counter of the number of deltas present in the queue. This counter is decremented by the Index Manager, after a delta has been processed. Clients wishing to reach a stable state can thus wait (interruptibly) upon this latch, that opens when the counter reaches zero.
Nonetheless, theoretically, nothing ensures that the latch will open eventually. In case deltas would continuously arrive in the queue, faster than their processing rate, clients would be waiting forever. However, this should seldom happen, as editing performed by humans is slow, while indexing performed by the computer is much quicker. To cater for the worse, the wait needs to be interruptible, so that clients can recover from any livelock.
Persistence
Workspace save
Index tables need to be persisted when the platform is shut down, so that the full index can be recovered at platform startup (rather than reconstructed expensively by running all indexers on all files). However, we don't want to save all index tables, but only essential information (the rest being reconstructed cheaply).
Stored data consists, for each project, in :
- declarations and their occurrences
- exports for each file
- dependencies between files
Moreover,the index manager must also persist its state, that is
- the list of deltas not yet fully processed when the platform shuts down
- the indexer registry
Upon startup, the delta list will be recovered and indexing resumed where it stopped.
If the indexer registry changes (e.g. indexers added), a full indexing will be scheduled to update the index with the new indexer configuration.
Project save
A single project needs to be saved when it gets closed.
Its indexed data becomes unnecessary, as the project is no more visible, so it is removed from the indexing system's memory and stored in a project specific file. It will be restored when the project is reopened.
Stored contents are the same as for a workspace save, restricted to the project in question.