Constrained Dynamic Parser: Difference between revisions
imported>Pascal |
imported>Pascal m →Typos |
||
| (23 intermediate revisions by 4 users not shown) | |||
| Line 1: | Line 1: | ||
{{TOCright}} | {{TOCright}} | ||
This page describes the requirements for a '''generic parser''' for the [[Event-B Mathematical Language]]. | This page describes the requirements for a '''generic parser''' for the [[Event-B Mathematical Language]]. | ||
| Line 5: | Line 6: | ||
== Requirements == | == Requirements == | ||
In order to be usable [[mathematical extensions]] require that the | In order to be usable, [[mathematical extensions]] require that the Event-B | ||
mathematical language syntax can be extended by the final user. | |||
The lexical analyser and the | The lexical analyser and the syntactic parser thus have to be extensible in a | ||
simple enough way (from a user point of view). | |||
=== Requirements Exported by the Current Language Design === | === Requirements Exported by the Current Language Design === | ||
==== Operator Priority ==== | ==== Operator Priority ==== | ||
* operator are | * operator are collected into groups, | ||
* | * precedence is defined between groups of operator, | ||
* there may be precedences defined inside groups. | * there may be precedences defined between operators inside groups. | ||
==== Operator Compatibility ==== | ==== Operator Compatibility ==== | ||
* a compatibility table defines allowed associativities inside a group, | * a compatibility table defines allowed associativities inside a group, | ||
* a compatibility table defines allowed associativities between groups (it allows to forbid a | * a compatibility table defines allowed associativities between groups (it allows to forbid a syntactic construction like <math>f(x)^{-1}\;</math>) | ||
: | : note: this requirement was added afterwards, with consistency in mind. | ||
=== Expected Extension Schemes === | === Expected Extension Schemes === | ||
We | We want at least define operators of the following form: | ||
* infix : <math>a + b\;</math> or <math>a \vdash b : c\;</math> | * infix : <math>a + b\;</math> or <math>a \vdash b : c\;</math> | ||
* prefix : <math>\neg a\;</math> | * prefix : <math>\neg a\;</math> | ||
| Line 31: | Line 34: | ||
* lambda like : <math> \lambda x\mapsto y . P | E\;</math> | * lambda like : <math> \lambda x\mapsto y . P | E\;</math> | ||
* Union like : <math> \Union\{ e \mid P\}</math> or <math> \Union\{ x,y . P \mid e\}</math> | * Union like : <math> \Union\{ e \mid P\}</math> or <math> \Union\{ x,y . P \mid e\}</math> | ||
* | * set like : <math>\{a, b, c + e\}\;</math> or <math>\{ e \mid P\}\;</math> or <math>\{x,y . P \mid e\}\;</math> | ||
We also | We also want to define precisely precedence and associativity between existing and new operators. | ||
=== Requirements exported by the dynamic feature === | === Requirements exported by the dynamic feature === | ||
* the precedence should not be enumerated but defined by a relation, like: '+' | * the precedence should not be enumerated, which would hinder extensibility, but defined by a relation, like: '+' < '*' and '*' < '**', ... | ||
== | == Design Alternatives == | ||
Three design alternatives where identified: | |||
=== Make Existing Parser Extensible === | === Make Existing Parser Extensible === | ||
The existing parser is a LL recursive descent parser generated by the [http://www.ssw.uni-linz.ac.at/Coco/ Coco/R Compiler Generator], which makes extensive use of pre-computed lookahead, | The existing parser is a LL recursive descent parser generated by the | ||
[http://www.ssw.uni-linz.ac.at/Coco/ Coco/R Compiler Generator], which makes | |||
extensive use of pre-computed lookahead, and then makes it very difficult to be | |||
transformed in a parser with enough extensibility. | |||
=== Parser Combinator === | === Parser Combinator === | ||
:* on [http://en.wikipedia.org/wiki/Parser_combinator wikipedia]. Some implementations are referenced [http://pdos.csail.mit.edu/~baford/packrat/ here]. | :* on [http://en.wikipedia.org/wiki/Parser_combinator wikipedia]. Some implementations are referenced [http://pdos.csail.mit.edu/~baford/packrat/ here]. | ||
:* with | :* with functional language [http://wiki.portal.chalmers.se/agda/Agda Agda] : ''[http://www.cs.nott.ac.uk/~nad/publications/danielsson-norell-mixfix.pdf Parsing Mixfix Operators]'' | ||
:: This paper is interesting in its proposal of using an acyclic graph to define operator precedence. | :: This paper is interesting in its proposal of using an acyclic graph to define operator precedence. | ||
:* with functional language [http://user.cs.tu-berlin.de/~opal/opal-language.html OPAL] : ''[http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=8A8A8B39FFBF1AEF17C782C4822C5AF6?doi=10.1.1.58.655&rep=rep1&type=url&i=0 How To Obtain Powerful Parsers That Are Elegant and Practical]'' | :* with functional language [http://user.cs.tu-berlin.de/~opal/opal-language.html OPAL] : ''[http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=8A8A8B39FFBF1AEF17C782C4822C5AF6?doi=10.1.1.58.655&rep=rep1&type=url&i=0 How To Obtain Powerful Parsers That Are Elegant and Practical]'' | ||
| Line 55: | Line 61: | ||
:* [http://effbot.org/zone/tdop-index.htm SImple ''Pratt'' parsing in python] | :* [http://effbot.org/zone/tdop-index.htm SImple ''Pratt'' parsing in python] | ||
:* [http://javascript.crockford.com/tdop/tdop.html ''Pratt'' parsing in javascript] | :* [http://javascript.crockford.com/tdop/tdop.html ''Pratt'' parsing in javascript] | ||
Note that a '' | Note that a ''Pratt'' parser is essentially a parser for expressions (where | ||
expression parts are themselves expressions)... But it may be tweaked to limit | |||
the accepted sub-expressions or to enforce some non-expression parts inside an | |||
expression. More on that hereafter. | |||
=== Some Existing Extensible Languages === | === Some Existing Extensible Languages === | ||
* [http://www.chrisseaton.com/katahdin/ Katahdin], and the associated paper [http://www.chrisseaton.com/katahdin/katahdin-thesis.pdf A Programming Language Where the Syntax and Semantics Are Mutable at Runtime] which describes the language and its implementation (in C#). | * [http://www.chrisseaton.com/katahdin/ Katahdin], and the associated paper [http://www.chrisseaton.com/katahdin/katahdin-thesis.pdf A Programming Language Where the Syntax and Semantics Are Mutable at Runtime] which describes the language and its implementation (in C#). | ||
* [http://itcentre.tvu.ac.uk/~clark/xmf.html XMF] whose implementation | * [http://itcentre.tvu.ac.uk/~clark/xmf.html XMF] whose implementation does not seem to be described in details. | ||
* [http://xlr.sourceforge.net/index.html XLR: Extensible Language and Runtime], which looks like a '' | * [http://xlr.sourceforge.net/index.html XLR: Extensible Language and Runtime], which looks like a ''Pratt'' parser according to the [http://xlr.svn.sourceforge.net/viewvc/xlr/trunk/xl2/xlr/parser.cpp?revision=805&view=markup sources]. | ||
* [http://www.pi-programming.org/What.html <math>\pi</math>] whose implementation | * [http://www.pi-programming.org/What.html <math>\pi</math>] whose implementation does not seem to be described in details (but source code is available). | ||
* Prolog and its operator declarations; see, e.g., [http://scholar.google.com/scholar?q=%22The+simple+and+powerful+yfx+operator+precedence+parser.%22 2007 paper]. | |||
== Design Proposal == | == Design Proposal == | ||
The chosen design is based on ''Pratt'' parser and is explained hereafter. | |||
=== Main Concepts === | === Main Concepts === | ||
;symbol: a symbol is a lexem known by the parser. | |||
;group: each symbol belongs to one and only one group. | ;symbol: a symbol is a lexem (<tt>finite</tt>, <math>\Union</math>, ...)or a lexem class (''number'', ''identifier'') known by the parser. | ||
;symbol compatibility: a relation telling if inside a group two symbol are | |||
:Two symbol are | ;group: each symbol belongs to one and only one group (''binary relation'', ''assignment substitution'',...). | ||
;group compatibility: a relation telling if two groups are | : ''Groups'' are used to ease the definition of a hierarchy between operators in order to ease the definition of precedence and compatibility. | ||
:Two symbol of different groups are said | |||
;symbol compatibility: a relation telling if inside a group two symbol are compatible. | |||
:Two symbol are compatible is they can be parsed without parentheses (see [[Event-B Mathematical Language]] for more on compatibility). | |||
;group compatibility: a relation telling if two groups are compatible. | |||
:Two symbol of different groups are said compatible if their group are compatible. | |||
;symbol associativity: a relation which gives the associative precedence of symbols inside a given group. | ;symbol associativity: a relation which gives the associative precedence of symbols inside a given group. | ||
;group associativity: a relation which gives the associative precedence of groups. | ;group associativity: a relation which gives the associative precedence of groups. | ||
:Two symbol of different groups have a relative precedence given by the associative precedence of their groups. | :Two symbol of different groups have a relative precedence given by the associative precedence of their groups. | ||
;generic parser: the parser which is defined. | ;generic parser: the parser which is defined. | ||
: This parser may be called recursively (an infix expression being build upon a left and right sub-expression) and is often the default parser used when building the AST associated with a ''symbol''. | : This parser may be called recursively (an infix expression being build upon a left and right sub-expression) and is often the default parser used when building the AST associated with a ''symbol''. | ||
;specific parser: some specific parser, predefined as helper functions to build specific AST. | ;specific parser: some specific parser, predefined as helper functions to build specific AST. | ||
: | |||
;nonterminal: A nonterminal is a set of symbol. Nonterminals are used for acceptance or rejection of the AST produced by a parser on a sub-formula. | |||
: ''nonterminals'' may be defined by mean of ''symbols'', ''groups'' or other ''nonterminals''. | |||
=== Proposed User Interface === | === Proposed User Interface === | ||
''The hereafter proposition does not preclude the final UI | ''The hereafter proposition does not preclude the final UI from taking other (more user friendly) form. But the concepts should probably stay the same''. | ||
We propose that the user will be able to create several predefined type of symbols (new types may certainly be further added by mean of | We propose that the user will be able to create several predefined type of | ||
symbols (new types may certainly be further added by mean of Eclipse extension | |||
points). When defining a symbol, the user can choose the parser used to parse | |||
the sub-expressions (default to generic parser, but a specific parser may be | |||
used) and can enforce the form of the resulting parsed sub-expression in terms | |||
of their AST root type. | |||
==== Predefined Symbol Builders ==== | ==== Predefined Symbol Builders ==== | ||
The proposed predefined symbol builders are: | The proposed predefined symbol builders are: | ||
;infix: For example predicate conjunction which expects two predicates for left and right parts may be defined by <code>infix("∧", gid="(logic pred)", expected_nonterm=["predicate", "predicate"])</code> | ;infix: For example, predicate conjunction, which expects two predicates for left and right parts, may be defined by <code>infix("∧", gid="(logic pred)", expected_nonterm=["predicate", "predicate"])</code>, saying that '∧' is an operator belonging to the ''logic predicate'' group which accept a predicate on left and right. | ||
:As another example, substitution | :As another example, substitution :∣ of group '(infix subst)' which expect one ''ident list'' for left term and a predicate for the right one may be defined by <code>infix(":∣", "(infix subst)", expected_nonterm=["ident_list", "predicate"])</code> | ||
;prefix: <code>prefix("¬", "(not pred)", expected_nonterm=["predicate"])</code> | ;prefix: <code>prefix("¬", "(not pred)", expected_nonterm=["predicate"])</code> | ||
| Line 93: | Line 121: | ||
;atomic: <code>atomic("⊤", "(atomic pred)")</code> | ;atomic: <code>atomic("⊤", "(atomic pred)")</code> | ||
;prefix closed: used to build prefix symbol which must be followed by enclosing symbol(brackets, parentheses,..). For example <tt>finite</tt> may be defined by: <code>prefix_closed("finite", "(", ")","(atomic pred)", expected_nonterm=["expression"])</code> | ;prefix closed: used to build prefix symbol which must be followed by enclosing symbol (brackets, parentheses,..). For example, <tt>finite</tt> may be defined by: <code>prefix_closed("finite", "(", ")","(atomic pred)", expected_nonterm=["expression"])</code> | ||
:postfix | :postfix; <code>postfix("∼", gid="(unary relation)", expected_nonterm=["expression"])</code> | ||
;quantified: <code>quantified("∀", "·", expected_nonterm=["predicate"]</code> | ;quantified: <code>quantified("∀", "·", expected_nonterm=["predicate"]</code> | ||
| Line 107: | Line 135: | ||
;functional postfix: <code>functional_postfix("(", ")", gid="(functional)", expected_nonterm=["expression", "expression"])</code> | ;functional postfix: <code>functional_postfix("(", ")", gid="(functional)", expected_nonterm=["expression", "expression"])</code> | ||
Some right associative versions of those symbol builders may also be supplied (infix_right, or a specific parameter ''right associative'' parameter may also be provided to the ''infix'' symbol builder). | Some right associative versions of those symbol builders may also be supplied | ||
(infix_right, or a specific parameter ''right associative'' parameter may also | |||
be provided to the ''infix'' symbol builder). | |||
==== Predefined Specific Parser ==== | ==== Predefined Specific Parser ==== | ||
| Line 144: | Line 174: | ||
("×", "×"), ] | ("×", "×"), ] | ||
</code> | </code> | ||
which defines the compatibility table for expression binary operator as defined in [[Event-B Mathematical Language]]. | which defines the compatibility table for expression binary operator, as defined in [[Event-B Mathematical Language]]. | ||
| Line 175: | Line 205: | ||
group_compatibility.add_all( [ "(binop)", "(interval)", (arithmetic)", "(unary relation)", "(unary relation)", "(bound unary)",....]) | group_compatibility.add_all( [ "(binop)", "(interval)", (arithmetic)", "(unary relation)", "(unary relation)", "(bound unary)",....]) | ||
</code> | </code> | ||
==== Defining Non-terminal Sets ==== | |||
The user shall have a mean to define new non-terminal sets and to extend existing ones. Thus, a new predicate operator shall be added to the ''predicate'' non-terminal. | |||
There shall be some predefined non-terminal sets: | |||
* ''predicate'' | |||
* ''expression'' | |||
* ''typing_predicate'' | |||
* ''name_or_emptyset'' (used by the typing operator) | |||
* ''ident_list'' (used by lambda like,...) | |||
==== Some Difficulties ==== | ==== Some Difficulties ==== | ||
Some difficulties appear when trying to implement an Event-B parser with the preceding scheme: | Some difficulties appear when trying to implement an Event-B parser with the preceding scheme: | ||
* A symbol may be declared by several different builders (think of unary and infix minus for example). | * A symbol may be declared by several different builders (think of unary and infix minus for example). | ||
: ''Pratt'' parsers are able to cope with a symbol appearing either at the beginning of an expression or inside an expression (see ''led'' and ''nud'' hereafter). For example, unary minus and infix minus can be both defined by the proposed scheme. However, in their default form, '' | : ''Pratt'' parsers are able to cope with a symbol appearing either at the beginning of an expression or inside an expression (see ''led'' and ''nud'' hereafter). For example, unary minus and infix minus can be both defined by the proposed scheme. However, in their default form, ''Pratt'' parser failed in parsing symbol like '{' which appears at the beginning of extension sets, comprehension sets and quantified sets. | ||
: SOLUTION #1: The existing Event-B parser uses an infinite lookahead to determine which one of those three sets is actually being parsed. | :: '''SOLUTION #1''': The existing Event-B parser uses an infinite lookahead to determine which one of those three sets is actually being parsed. | ||
: This solution hinders the extensibility of the parser, because the addition of a symbol requires to modify the lookahead. | :: This solution hinders the extensibility of the parser, because the addition of a symbol requires to modify the lookahead. | ||
: However, such an issue may be bypassed, at least in a first version, in enforcing some usage rules. Thus, a new symbol contributed by an extension but used in the lookahead may be rejected as in invalid symbol. | :: However, such an issue may be bypassed, at least in a first version, in enforcing some usage rules. Thus, a new symbol contributed by an extension but used in the lookahead may be rejected as in invalid symbol. | ||
: SOLUTION #2: Implementing a backtracking parser. | :: '''SOLUTION #2''': Implementing a backtracking parser. | ||
: More precisely, it means that the three sets | :: More precisely, it means that the parsing is attempted on every alternative (for example, on the three types of sets parser: extension, comprehension, and quantified). The parsing is successful if and only if one of these attempts lead to a result (''i.e''., it is a failure if several attempts or none lead to a result). All the error are collected and returned to the user in case of no match. | ||
: It is a good solution provided that we use memorisation to alleviate the cost of parsing formulas that require heavy backtracking. | :: It is a good solution provided that we use memorisation to alleviate the cost of parsing formulas that require heavy backtracking. | ||
* Some binary infix operators are in fact parsed as n-ary operators (with more than 2 childrens if possible). | * Some binary infix operators are in fact parsed as n-ary operators (with more than 2 childrens if possible). | ||
: An attribute is required to specify if an operator shall be flattened (i.e., parsed as an n-ary operator) or not. It is indeed impossible to "deduce" this information (e.g., the minus operator, which is left associative and self-compatible, shall not be flattened). | : An attribute is required to specify if an operator shall be flattened (i.e., parsed as an n-ary operator) or not. It is indeed impossible to "deduce" this information (e.g., the minus operator, which is left associative and self-compatible, shall not be flattened). | ||
: The flattening should then be done by the parser associated to every symbol. | |||
* The returned parsing errors shall be meaningful for users (e.g., the "Missing parenthesis" message may help to solve the problem when the "Invalid expression" message is too imprecise). | * The returned parsing errors shall be meaningful for users (e.g., the "Missing parenthesis" message may help to solve the problem when the "Invalid expression" message is too imprecise). | ||
:{{TODO|describe error reporting within the proposed design}}. | |||
* Defining a grammar or a grammar extension is not an easy job, even with those simple mechanisms. | * Defining a grammar or a grammar extension is not an easy job, even with those simple mechanisms. | ||
: It would certainly be a good idea to implement a user interface to test the grammar, so that an extension designer has a way to ensure that he agrees with the parser on the semantic of his extension (or at least on the AST obtained by using it). For example, the representation of the syntax tree returned by <tt>Formula.getSyntaxTree</tt> could be compared to an expected entered string. | : It would certainly be a good idea to implement a user interface to test the grammar, so that an extension designer has a way to ensure that he agrees with the parser on the semantic of his extension (or at least on the AST obtained by using it). For example, the representation of the syntax tree returned by <tt>Formula.getSyntaxTree</tt> could be compared to an expected entered string. | ||
=== Limitations === | |||
In a first implementation, we do not want to support several alternative for one symbol (using backtracking -- see [[#Some Difficulties|here before]]). As a side effect, it won't be possible to define new ''lambda like'', ''union like'' and ''sets like'' terms, or terms that use one of the following symbol: λ, ⋂, ⋃ or ∣. | |||
=== Core Algorithm === | === Core Algorithm === | ||
==== Rough description ==== | |||
The algorithm is based on a table, associating a ''SymbolParser'' for each | |||
known operator (or lexem class). The ''MainParser'' then constructs the AST by | |||
using the ''led'' or ''nud'' parser instance attached to each symbol, taking | |||
into account symbol information such as group and precedence to construct the | |||
resulting AST. | |||
Each ''led'' or ''nud'' parser instance may in turn make recursive calls to | |||
either the standard ''MainParser'' or to ad-hoc parsers. The choice of the | |||
sub-parsers used is given when the ''SymbolParser'' is created. | |||
==== Parsing an Example ==== | |||
We will try to explain how the parser manage to build an AST from the input ''2 * 3 + a''. | |||
Firstly, ''MainParser'' will call the ''nud'' function of the parser associated | |||
to the ''literal'' symbol valued with '2', which simply return an AST node | |||
''(literal 2)''. | |||
''MainParser'' will then pass this AST to the ''led'' | |||
function of the parser associated to the '*' operator, which will use it for | |||
its left child and will then call ''MainParser'' to recognize its right term. | |||
This new call to ''MainParser'' will in turn build the AST node ''(literal 3)'' | |||
and then will return, because of precedences between the current AST being build ('*') and the next lexem ('+') which does not allow to build a ''('+' (literal 3) (name a))'' sub-expression. | |||
The initial ''MainParser'' call now get the following left term: ''('*' (literal 2) (literal 3))'' and then call the ''led'' function associated to the | |||
'+' operator, which will in turn call ''MainParser'' which will return the simple | |||
AST ''(ident a)'' and build the resulting AST: ''('+' ('*' (literal 2) (literal | |||
3)) (name a) )''. | |||
==== Main Objects ==== | ==== Main Objects ==== | ||
;{{class|KnownSymbols}}: a table associating a {{class|SymbolParser}} for each known symbol. | ;{{class|KnownSymbols}}: a table associating a {{class|SymbolParser}} for each known symbol. | ||
;{{class|Tokenizer}} {{ident|tokenizer}}: which provides the {{class|SymbolParser}} associated to the next lexem of the formula being parsed. | |||
: {{TODO|shall be a singleton ? }} | |||
;{{class|SymbolParser}}: a Parser for a specific symbol. It should at least have the following attributes: | ;{{class|SymbolParser}}: a Parser for a specific symbol. It should at least have the following attributes: | ||
:* {{class|Array< | :* {{class|Array<LedParser>}} {{ident|led_parsers}} for parsing the expression associated to the symbol {{ident|id}} when it appears in the middle of an expression (''left denotation'') | ||
:* {{class|Array< | :* {{class|Array<NudParser>}} {{ident|nud_parsers}} for parsing the expression associated to the symbol {{ident|id}} when it appears at the beginning of an expression (''null denotation'') | ||
:* {{class|String}} {{ident|id}} | :* {{class|String}} {{ident|id}} which is the lexem concerned by those parsers. | ||
:* {{class|String}} {{ident|gid}} designing the group to which the {{ident|id}} symbol belongs to. | :* {{class|String}} {{ident|gid}} designing the group to which the {{ident|id}} symbol belongs to. | ||
:Note that parsers in ''led'' (respectively ''nud'') will be tried one after another | :* {{ident|bool flat_ast}} true if the associated binary AST shall be flatten in an n-ary AST. | ||
:and the following members: | |||
:*<code>AST led(AST left)</code>: which should iterate with backtracking over led_parsers.led() | |||
:*<code>AST nud(AST left)</code>: which should iterate with backtracking over nud_parsers.nud() | |||
:Note that parsers in ''led'' (respectively ''nud'') will be tried one after another (with backtracking to the original state in between). If several of them succeed, an error is returned to the user, else the AST generated by the only one succeeding is returned. If none succeeded, an error is raised. | |||
;{{class| | ;{{class|LedOrNudParser}}: An abstract parser, that may be used by the {{class|MainParser}}, which should have the following attributes | ||
:*{{class|Parser | :*{{class|Array<Parser>}} {{ident|subparsers}}: an array of sub-parsers used by the {{ident|parse}} method. They defaults to {{ident|MainParser}}, but may be set to specific parsers. | ||
:*{{class|Array<NonterminalSet>}} {{ident|nonterminals}}: set of non-terminals that are expected to be return by the ''parse'' function of the associated sub-parser (with the same index). If the root of the AST returned by the ''parse'' function is not one of the expected nonterminals, then an error is raised stating which non-terminals were expected, and which one was found. | |||
:*{{ | |||
;{{class| | ;{{class|LedParser}}: An abstract parser which inherits from {{class|LedOrNudParser}} and provides the following method: | ||
:*{{ident| | :*<code>AST led(AST left)</code>: which given an already parsed ''left'' AST will construct the AST associated to the lexem being parsed, by analysing the part of the formula on its right. This method is responsible for verifying that the returned AST has one of the expected type (see {{class|LedOrNudParser}}#{{ident|nonterminals}}) | ||
;{{class|NudParser}}: An abstract parser which inherits from {{class|LedOrNudParser}} and provides the following method: | |||
:*<code>AST nud()</code>: which build an AST associated to the lexem being parsed, by analysing the part of the formula on its right. This method is responsible for verifying that the returned AST has one of the expected type (see {{class|LedOrNudParser}}#{{ident|nonterminals}}) | |||
;{{class|Parser}}: An abstract class of a ''recursive descent like parser'' which is used by the ''led'' or ''nud'' functions to build parts from AST. It may be instantiated by the ''MainParser'' or by any specific parser (used to parse list of identifier, or other structures that do not fit well in the general ''Pratt'' parser schema ...). | |||
:and the following method: | |||
:*<code>AST parse()</code>: this method should consume tokens provided by the ''tokenizer'' and returns an AST. It may use several {{ident|subparsers}}. | |||
;{{class|MainParser}} | ;{{class|MainParser}} | ||
:This class inherits from {{class|Parser }} and its {{ident|parse}} function implements the core of the '' | :This class inherits from {{class|Parser}} and its {{ident|parse}} function implements the core of the ''Pratt'' algorithm. | ||
:Without taking into account backtracking, the algorithm reads: | :Without taking into account backtracking, the algorithm reads: | ||
| Line 232: | Line 322: | ||
</pre></code></blockquote> | </pre></code></blockquote> | ||
:The parsing of a new expression is initiated by: | The ''has_less_priority'' function used the compatibility and precedence relations to determine if the next token should be parsed as a part of the current expression of should be left over for the calling parser. I may looks like: | ||
* when the recognize symbol is left associative: | |||
<blockquote><code><pre> | |||
def has_less_priority_than(self, other , is_right_associative=False): | |||
# every operator of group 0 is not associative | |||
if (self.gid == u"0" and other.gid == u"0"): | |||
return False | |||
if (self.gid, other.gid) in group_associativity: | |||
return True | |||
elif (other.gid, self.gid) in group_associativity: | |||
return False | |||
elif (other.gid, self.gid) not in group_compatibility: | |||
raise SyntaxError | |||
elif self.gid == other.gid: | |||
if (self.id, other.id) in group[self.gid].operator_associativity: | |||
return True # right associativity | |||
if (other.id, self.id) in group[self.gid].operator_associativity: | |||
return False # left associativity | |||
if group[self.gid].is_compatible(self.id, other.id): #raise SyntaxError if not compatible | |||
return False # left associativity is chosen for | |||
# compatible operators | |||
raise AssertionError("Should not be reached") | |||
else: | |||
return False | |||
</pre></code></blockquote> | |||
* when the recognize symbol is right associative: | |||
<blockquote><code><pre> | |||
def has_less_priority_than(self, other , is_right_associative=False): | |||
if (self.gid == u"0" and other.gid == u"0"): | |||
return False | |||
if (self.gid, other.gid) in group_associativity: | |||
return True | |||
elif (other.gid, self.gid) in group_associativity: | |||
return False | |||
elif (other.gid, self.gid) not in group_compatibility: | |||
raise SyntaxError | |||
elif self.gid == other.gid: | |||
if (self.id, other.id) in group[self.gid].operator_associativity: | |||
return False # lef associativity | |||
if (other.id, self.id) in group[self.gid].operator_associativity: | |||
return True # right associativity | |||
if group[self.gid].is_compatible(self.id, other.id) : | |||
return True | |||
raise AssertionError("Should not be reached") | |||
else: | |||
return False | |||
</pre></code></blockquote> | |||
'''Note''' that while ''group_compatibility'' is really a relation, ''group_associativity'' is more a closure on associativity relation. | |||
:The parsing of a new expression is then initiated by: | |||
<blockquote><code><pre> | <blockquote><code><pre> | ||
token = tokenizer.next() | token = tokenizer.next() | ||
| Line 238: | Line 378: | ||
</pre></code></blockquote> | </pre></code></blockquote> | ||
;{{class|identListParser}}: inherits from {{class|Parser}}. Its {{ident|parse}} function implements the parsing of an ident list (like <math>a,b,c\;</math>). | ;{{class|identListParser}}: inherits from {{class|Parser}}. Its {{ident|parse}} function implements the parsing of an ident list (like <math>a,b,c\;</math>). | ||
;{{class|identMapletListParser}}: inherits from {{class|Parser }}. Its {{ident|parse}} function implements the parsing of a maplet list as used in lambda expression (like <math>a \mapsto (b \mapsto c)\;</math>). | ;{{class|identMapletListParser}}: inherits from {{class|Parser }}. Its {{ident|parse}} function implements the parsing of a maplet list as used in lambda expression (like <math>a \mapsto (b \mapsto c)\;</math>). | ||
;{{class|expressionListParser}}: inherits from {{class|Parser }}. Its {{ident|parse}} function implements a list of expression as used in the extension set expression. | ;{{class|expressionListParser}}: inherits from {{class|Parser }}. Its {{ident|parse}} function implements a list of expression as used in the extension set expression. | ||
;{{class|infixParser}}: inherits from {{class|LedParser}}. Its {{ident|led}} function implements something like (pseudocode): | |||
;{{class|infixParser}}: inherits from {{class| | |||
<blockquote><code><pre> | <blockquote><code><pre> | ||
led(AST left, Symbol value): | |||
ast = new AST() | ast = new AST(this.id, this.gid, value) | ||
ast.first = left | ast.first = left | ||
verify_expected_group(ast.first, this.expected_non_terminals[0]) | verify_expected_group(ast.first, this.expected_non_terminals[0]) | ||
ast.second = this. | ast.second = this.subparsers[0].parse(ast, is_right_associative=False) | ||
# is_right_associative parameter should be set to True for a right associative infix parser | |||
verify_expected_group(ast.second, this.expected_non_terminals[1]) | verify_expected_group(ast.second, this.expected_non_terminals[1]) | ||
if this.flat: | |||
# flatten the AST if ast.first or ast.second have the same root operator tha the AST being built. | |||
return ast | return ast | ||
</pre></code></blockquote> | </pre></code></blockquote> | ||
{{TODO|each parser should be passed a context to allow rewriting of bound identifiers on the AST being constructed. A special rewriting should be done for comprehension sets and alike, because the bound variables are not known before the parsing of the actual expression}} | |||
;{{class| | ;{{class|atomicParser}}: inherits from {{class|NudParser}}. Its {{ident|nud}} function implements something like (pseudocode): | ||
<blockquote><code><pre> | <blockquote><code><pre> | ||
if | nud(Symbol value): | ||
ast = new AST(this.id, this.gid, value) | |||
return ast | |||
</pre></code></blockquote> | |||
;{{class|postfixParser}}: inherits from {{class|LedParser}}. Its {{ident|led}} function implements something like (pseudo-code): | |||
<blockquote><code><pre> | |||
led(AST left, Symbol value): | |||
ast = new AST(this.id, this.gid, value) | |||
ast.first = left | |||
verify_expected_group(ast.first, this.expected_non_terminals[0]) | |||
if this.flat: | |||
# flatten the AST if ast.first or ast.second have the same root operator tha the AST being built. | |||
return ast | |||
</pre></code></blockquote> | |||
;{{class|prefixParser}}: inherits from {{class|NudParser}}. Its {{ident|nud}} function implements something like (pseudo-code): | |||
<blockquote><code><pre> | |||
nud(Symbol value): | |||
ast = new AST(this.id, this.gid, value) | |||
ast.first = this.subparsers[0].parse(ast, is_right_associative=False) | |||
verify_expected_group(ast.first, this.expected_non_terminals[0]) | |||
if this.flat: | |||
# flatten the AST if ast.first or ast.second have the same root operator tha the AST being built. | |||
return ast | |||
</pre></code></blockquote> | |||
;{{class|functionalPostfixParser}}: inherits from {{class|LedParser}}. It has a supplementary {ident|close_symbol}} attribute, and its {{ident|led}} function implements something like (pseudo-code): | |||
<blockquote><code><pre> | |||
led(AST left, Symbol value): | |||
ast = new AST(this.id, this.gid, value) | |||
ast.first = left | |||
verify_expected_group(ast.first, this.expected_non_terminals[0]) | |||
ast.second = this.subparsers[0].parse(ast, is_right_associative=False) | |||
# is_right_associative parameter should be set to True for a right associative infix parser | |||
verify_expected_group(ast.second, this.expected_non_terminals[1]) | |||
this.tokenizer.advance(this.close_symbol) #consume the close symbol or raise a SyntaxError | |||
return ast | |||
</pre></code></blockquote> | </pre></code></blockquote> | ||
=== Open Questions === | === Open Questions === | ||
| Line 269: | Line 447: | ||
: Some examples in the existing parser: | : Some examples in the existing parser: | ||
:* Bound identifiers are converted to ''de Bruijn'' indexes while constructing the AST. Is this desirable ? How does the user specify that identifier are bound or not ? | :* Bound identifiers are converted to ''de Bruijn'' indexes while constructing the AST. Is this desirable ? How does the user specify that identifier are bound or not ? | ||
:: In fact, the rewriting of bound identifier is done in the pre-existing parsers, so there is no need for the user to specify if an identifier will be bound or not. The user has just to select the parser he want to use (lambda like, set like, ...) | |||
=== Sample Implementation === | === Sample Implementation === | ||
A prototype as been developed in Python to quickly try different solutions. | A prototype as been developed in Python to quickly try different solutions. | ||
The development tree of the python prototype is available at http://bitbucket.org/matclab/eventb_pratt_parser/ | The development tree of the python prototype is available at http://bitbucket.org/matclab/eventb_pratt_parser/ with the ''default'' branch implementing a rather functional approach and the ''object'' branch being a first try to a more object based implementation. | ||
=== Tests === | |||
* Regression tests. The tests of the existing parser shall succeed when applied to the generic parser. | |||
* New tests. | |||
[[Category:Design | [[Category:Design proposal]] | ||
Latest revision as of 13:21, 15 February 2010
This page describes the requirements for a generic parser for the Event-B Mathematical Language.
A first design proposal is also drafted.
Requirements
In order to be usable, mathematical extensions require that the Event-B mathematical language syntax can be extended by the final user.
The lexical analyser and the syntactic parser thus have to be extensible in a simple enough way (from a user point of view).
Requirements Exported by the Current Language Design
Operator Priority
- operator are collected into groups,
- precedence is defined between groups of operator,
- there may be precedences defined between operators inside groups.
Operator Compatibility
- a compatibility table defines allowed associativities inside a group,
- a compatibility table defines allowed associativities between groups (it allows to forbid a syntactic construction like
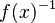 )
)
- note: this requirement was added afterwards, with consistency in mind.
Expected Extension Schemes
We want at least define operators of the following form:
- infix :
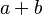 or
or 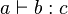
- prefix :
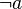
- postfix :
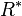
- closed :
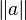
- parentheses sugar :
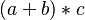
- functional postfix :
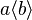
- functional prefix :
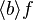
- lambda like :
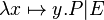
- Union like :
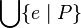 or
or 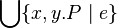
- set like :
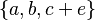 or
or 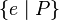 or
or 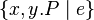
We also want to define precisely precedence and associativity between existing and new operators.
Requirements exported by the dynamic feature
- the precedence should not be enumerated, which would hinder extensibility, but defined by a relation, like: '+' < '*' and '*' < '**', ...
Design Alternatives
Three design alternatives where identified:
Make Existing Parser Extensible
The existing parser is a LL recursive descent parser generated by the Coco/R Compiler Generator, which makes extensive use of pre-computed lookahead, and then makes it very difficult to be transformed in a parser with enough extensibility.
Parser Combinator
- on wikipedia. Some implementations are referenced here.
- with functional language Agda : Parsing Mixfix Operators
- This paper is interesting in its proposal of using an acyclic graph to define operator precedence.
- with functional language OPAL : How To Obtain Powerful Parsers That Are Elegant and Practical
Pratt Parser
Note that a Pratt parser is essentially a parser for expressions (where expression parts are themselves expressions)... But it may be tweaked to limit the accepted sub-expressions or to enforce some non-expression parts inside an expression. More on that hereafter.
Some Existing Extensible Languages
- Katahdin, and the associated paper A Programming Language Where the Syntax and Semantics Are Mutable at Runtime which describes the language and its implementation (in C#).
- XMF whose implementation does not seem to be described in details.
- XLR: Extensible Language and Runtime, which looks like a Pratt parser according to the sources.
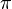 whose implementation does not seem to be described in details (but source code is available).
whose implementation does not seem to be described in details (but source code is available).- Prolog and its operator declarations; see, e.g., 2007 paper.
Design Proposal
The chosen design is based on Pratt parser and is explained hereafter.
Main Concepts
- symbol
- a symbol is a lexem (finite,
 , ...)or a lexem class (number, identifier) known by the parser.
, ...)or a lexem class (number, identifier) known by the parser.
- group
- each symbol belongs to one and only one group (binary relation, assignment substitution,...).
- Groups are used to ease the definition of a hierarchy between operators in order to ease the definition of precedence and compatibility.
- symbol compatibility
- a relation telling if inside a group two symbol are compatible.
- Two symbol are compatible is they can be parsed without parentheses (see Event-B Mathematical Language for more on compatibility).
- group compatibility
- a relation telling if two groups are compatible.
- Two symbol of different groups are said compatible if their group are compatible.
- symbol associativity
- a relation which gives the associative precedence of symbols inside a given group.
- group associativity
- a relation which gives the associative precedence of groups.
- Two symbol of different groups have a relative precedence given by the associative precedence of their groups.
- generic parser
- the parser which is defined.
- This parser may be called recursively (an infix expression being build upon a left and right sub-expression) and is often the default parser used when building the AST associated with a symbol.
- specific parser
- some specific parser, predefined as helper functions to build specific AST.
- nonterminal
- A nonterminal is a set of symbol. Nonterminals are used for acceptance or rejection of the AST produced by a parser on a sub-formula.
- nonterminals may be defined by mean of symbols, groups or other nonterminals.
Proposed User Interface
The hereafter proposition does not preclude the final UI from taking other (more user friendly) form. But the concepts should probably stay the same.
We propose that the user will be able to create several predefined type of symbols (new types may certainly be further added by mean of Eclipse extension points). When defining a symbol, the user can choose the parser used to parse the sub-expressions (default to generic parser, but a specific parser may be used) and can enforce the form of the resulting parsed sub-expression in terms of their AST root type.
Predefined Symbol Builders
The proposed predefined symbol builders are:
- infix
- For example, predicate conjunction, which expects two predicates for left and right parts, may be defined by
infix("∧", gid="(logic pred)", expected_nonterm=["predicate", "predicate"]), saying that '∧' is an operator belonging to the logic predicate group which accept a predicate on left and right. - As another example, substitution :∣ of group '(infix subst)' which expect one ident list for left term and a predicate for the right one may be defined by
infix(":∣", "(infix subst)", expected_nonterm=["ident_list", "predicate"])
- prefix
prefix("¬", "(not pred)", expected_nonterm=["predicate"])
- atomic
atomic("⊤", "(atomic pred)")
- prefix closed
- used to build prefix symbol which must be followed by enclosing symbol (brackets, parentheses,..). For example, finite may be defined by:
prefix_closed("finite", "(", ")","(atomic pred)", expected_nonterm=["expression"])
- postfix;
postfix("∼", gid="(unary relation)", expected_nonterm=["expression"])
- quantified
quantified("∀", "·", expected_nonterm=["predicate"]
- lambda like
lambda_like("λ", "·", u"∣", gid="(quantification)", expected_nonterm=["ident list", "predicate", "expression"])
- quantified union like
Union_like("⋃", "·", "∣", gid="(quantification)")
- closed sugar
- use for parentheses added to enforce associativity:
closed_sugar("(", ")")
- functional postfix
functional_postfix("(", ")", gid="(functional)", expected_nonterm=["expression", "expression"])
Some right associative versions of those symbol builders may also be supplied (infix_right, or a specific parameter right associative parameter may also be provided to the infix symbol builder).
Predefined Specific Parser
- expression lists
- ident lists
- maplet tree (for lambda)
Defining Compatibility and Precedences
Inside a group, compatibility may be defined like:
g = group["(binop)"]
g.add_many_compatibility(
[ ("∪", "∪"),
("∩", "∩"),
("∩", "∖"),
("∩", "▷"),
("∩", "⩥"),
("∘", "∘"),
(";", ";"),
(";", "▷"),
(";", "⩥"),
("", ""),
("◁", "∩"),
("◁", "∖"),
("◁", ";"),
("◁", "⊗"),
("◁", "▷"),
("◁", "⩥"),
("⩥", "∩"),
("⩥", "∖"),
("⩥", ";"),
("⩥", "⊗"),
("⩥", "▷"),
("⩥", "⩥"),
("×", "×"), ]
which defines the compatibility table for expression binary operator, as defined in Event-B Mathematical Language.
Inside a group, precedence may be defined like:
g = group["(arithmetic)"]
g.add_many_precedence(
[ ("^", "÷"),
("^", "∗"),
("^", "+"),
("^", "−"),
("^", "mod"),
("+", "∗"),
("−", "∗"),
("+", "÷"),
("−", "÷"),
("+", "mod"),
("−", "mod"), ] )
which defines ^ as having the least precedence amongst the operators of the expression arithmetic group.
Similarly, precedences and compatibilities between groups may be defined :
group_precedence.add(("(binop)", "(interval)"))
group_precedence.add(("(interval)", "(arithmetic)"))
group_precedence.add(("(arithmetic)", "(unary relation)"))
group_precedence.add(("(unary relation)", "(bound unary)"))
group_precedence.add(( "(bound unary)", "(bool)"))
group_compatibility.add_all( [ "(binop)", "(interval)", (arithmetic)", "(unary relation)", "(unary relation)", "(bound unary)",....])
Defining Non-terminal Sets
The user shall have a mean to define new non-terminal sets and to extend existing ones. Thus, a new predicate operator shall be added to the predicate non-terminal. There shall be some predefined non-terminal sets:
- predicate
- expression
- typing_predicate
- name_or_emptyset (used by the typing operator)
- ident_list (used by lambda like,...)
Some Difficulties
Some difficulties appear when trying to implement an Event-B parser with the preceding scheme:
- A symbol may be declared by several different builders (think of unary and infix minus for example).
- Pratt parsers are able to cope with a symbol appearing either at the beginning of an expression or inside an expression (see led and nud hereafter). For example, unary minus and infix minus can be both defined by the proposed scheme. However, in their default form, Pratt parser failed in parsing symbol like '{' which appears at the beginning of extension sets, comprehension sets and quantified sets.
- SOLUTION #1: The existing Event-B parser uses an infinite lookahead to determine which one of those three sets is actually being parsed.
- This solution hinders the extensibility of the parser, because the addition of a symbol requires to modify the lookahead.
- However, such an issue may be bypassed, at least in a first version, in enforcing some usage rules. Thus, a new symbol contributed by an extension but used in the lookahead may be rejected as in invalid symbol.
- SOLUTION #2: Implementing a backtracking parser.
- More precisely, it means that the parsing is attempted on every alternative (for example, on the three types of sets parser: extension, comprehension, and quantified). The parsing is successful if and only if one of these attempts lead to a result (i.e., it is a failure if several attempts or none lead to a result). All the error are collected and returned to the user in case of no match.
- It is a good solution provided that we use memorisation to alleviate the cost of parsing formulas that require heavy backtracking.
- Some binary infix operators are in fact parsed as n-ary operators (with more than 2 childrens if possible).
- An attribute is required to specify if an operator shall be flattened (i.e., parsed as an n-ary operator) or not. It is indeed impossible to "deduce" this information (e.g., the minus operator, which is left associative and self-compatible, shall not be flattened).
- The flattening should then be done by the parser associated to every symbol.
- The returned parsing errors shall be meaningful for users (e.g., the "Missing parenthesis" message may help to solve the problem when the "Invalid expression" message is too imprecise).
- TODO: describe error reporting within the proposed design.
- Defining a grammar or a grammar extension is not an easy job, even with those simple mechanisms.
- It would certainly be a good idea to implement a user interface to test the grammar, so that an extension designer has a way to ensure that he agrees with the parser on the semantic of his extension (or at least on the AST obtained by using it). For example, the representation of the syntax tree returned by Formula.getSyntaxTree could be compared to an expected entered string.
Limitations
In a first implementation, we do not want to support several alternative for one symbol (using backtracking -- see here before). As a side effect, it won't be possible to define new lambda like, union like and sets like terms, or terms that use one of the following symbol: λ, ⋂, ⋃ or ∣.
Core Algorithm
Rough description
The algorithm is based on a table, associating a SymbolParser for each known operator (or lexem class). The MainParser then constructs the AST by using the led or nud parser instance attached to each symbol, taking into account symbol information such as group and precedence to construct the resulting AST.
Each led or nud parser instance may in turn make recursive calls to either the standard MainParser or to ad-hoc parsers. The choice of the sub-parsers used is given when the SymbolParser is created.
Parsing an Example
We will try to explain how the parser manage to build an AST from the input 2 * 3 + a.
Firstly, MainParser will call the nud function of the parser associated to the literal symbol valued with '2', which simply return an AST node (literal 2).
MainParser will then pass this AST to the led function of the parser associated to the '*' operator, which will use it for its left child and will then call MainParser to recognize its right term.
This new call to MainParser will in turn build the AST node (literal 3) and then will return, because of precedences between the current AST being build ('*') and the next lexem ('+') which does not allow to build a ('+' (literal 3) (name a)) sub-expression.
The initial MainParser call now get the following left term: ('*' (literal 2) (literal 3)) and then call the led function associated to the '+' operator, which will in turn call MainParser which will return the simple AST (ident a) and build the resulting AST: ('+' ('*' (literal 2) (literal 3)) (name a) ).
Main Objects
- KnownSymbols
- a table associating a SymbolParser for each known symbol.
- Tokenizer tokenizer
- which provides the SymbolParser associated to the next lexem of the formula being parsed.
- TODO: shall be a singleton ?
- SymbolParser
- a Parser for a specific symbol. It should at least have the following attributes:
- Array<LedParser> led_parsersfor parsing the expression associated to the symbolidwhen it appears in the middle of an expression (left denotation)
- Array<NudParser> nud_parsersfor parsing the expression associated to the symbolidwhen it appears at the beginning of an expression (null denotation)
- String idwhich is the lexem concerned by those parsers.
- String giddesigning the group to which theidsymbol belongs to.
- bool flat_asttrue if the associated binary AST shall be flatten in an n-ary AST.
- Array<LedParser>
- and the following members:
AST led(AST left): which should iterate with backtracking over led_parsers.led()AST nud(AST left): which should iterate with backtracking over nud_parsers.nud()
- Note that parsers in led (respectively nud) will be tried one after another (with backtracking to the original state in between). If several of them succeed, an error is returned to the user, else the AST generated by the only one succeeding is returned. If none succeeded, an error is raised.
- LedOrNudParser
- An abstract parser, that may be used by the MainParser, which should have the following attributes
- Array<Parser> subparsers: an array of sub-parsers used by theparsemethod. They defaults toMainParser, but may be set to specific parsers.
- Array<NonterminalSet> nonterminals: set of non-terminals that are expected to be return by the parse function of the associated sub-parser (with the same index). If the root of the AST returned by the parse function is not one of the expected nonterminals, then an error is raised stating which non-terminals were expected, and which one was found.
- Array<Parser>
- LedParser
- An abstract parser which inherits from LedOrNudParser and provides the following method:
AST led(AST left): which given an already parsed left AST will construct the AST associated to the lexem being parsed, by analysing the part of the formula on its right. This method is responsible for verifying that the returned AST has one of the expected type (see LedOrNudParser#nonterminals)
- NudParser
- An abstract parser which inherits from LedOrNudParser and provides the following method:
AST nud(): which build an AST associated to the lexem being parsed, by analysing the part of the formula on its right. This method is responsible for verifying that the returned AST has one of the expected type (see LedOrNudParser#nonterminals)
- Parser
- An abstract class of a recursive descent like parser which is used by the led or nud functions to build parts from AST. It may be instantiated by the MainParser or by any specific parser (used to parse list of identifier, or other structures that do not fit well in the general Pratt parser schema ...).
- and the following method:
AST parse(): this method should consume tokens provided by the tokenizer and returns an AST. It may use severalsubparsers.
- MainParser
- This class inherits from Parser and its parsefunction implements the core of the Pratt algorithm.
- Without taking into account backtracking, the algorithm reads:
def parse(reckognized_token, has_right_associativity=False):
global token
t = token # t is the processed symbol
token = tokenizer.next() # token is the next symbol
left = t.nud() # a new expression is being parsed (null denotation : nothing on the left)
while has_less_priority(reckognized_token, token, has_right_associativity):
t = token
token = next_token() # if precedence allows it, we parse next expression
left = t.led(left) # has being left expression of current symbol (left denotation)
return left
The has_less_priority function used the compatibility and precedence relations to determine if the next token should be parsed as a part of the current expression of should be left over for the calling parser. I may looks like:
- when the recognize symbol is left associative:
def has_less_priority_than(self, other , is_right_associative=False):
# every operator of group 0 is not associative
if (self.gid == u"0" and other.gid == u"0"):
return False
if (self.gid, other.gid) in group_associativity:
return True
elif (other.gid, self.gid) in group_associativity:
return False
elif (other.gid, self.gid) not in group_compatibility:
raise SyntaxError
elif self.gid == other.gid:
if (self.id, other.id) in group[self.gid].operator_associativity:
return True # right associativity
if (other.id, self.id) in group[self.gid].operator_associativity:
return False # left associativity
if group[self.gid].is_compatible(self.id, other.id): #raise SyntaxError if not compatible
return False # left associativity is chosen for
# compatible operators
raise AssertionError("Should not be reached")
else:
return False
- when the recognize symbol is right associative:
def has_less_priority_than(self, other , is_right_associative=False):
if (self.gid == u"0" and other.gid == u"0"):
return False
if (self.gid, other.gid) in group_associativity:
return True
elif (other.gid, self.gid) in group_associativity:
return False
elif (other.gid, self.gid) not in group_compatibility:
raise SyntaxError
elif self.gid == other.gid:
if (self.id, other.id) in group[self.gid].operator_associativity:
return False # lef associativity
if (other.id, self.id) in group[self.gid].operator_associativity:
return True # right associativity
if group[self.gid].is_compatible(self.id, other.id) :
return True
raise AssertionError("Should not be reached")
else:
return False
Note that while group_compatibility is really a relation, group_associativity is more a closure on associativity relation.
- The parsing of a new expression is then initiated by:
token = tokenizer.next()
ast = MainParser.parse(KnownSymbols["(eof)"])
- identListParser
- inherits from Parser. Its parsefunction implements the parsing of an ident list (like
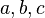 ).
).
- identMapletListParser
- inherits from Parser . Its parsefunction implements the parsing of a maplet list as used in lambda expression (like
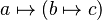 ).
).
- expressionListParser
- inherits from Parser . Its parsefunction implements a list of expression as used in the extension set expression.
- infixParser
- inherits from LedParser. Its ledfunction implements something like (pseudocode):
led(AST left, Symbol value):
ast = new AST(this.id, this.gid, value)
ast.first = left
verify_expected_group(ast.first, this.expected_non_terminals[0])
ast.second = this.subparsers[0].parse(ast, is_right_associative=False)
# is_right_associative parameter should be set to True for a right associative infix parser
verify_expected_group(ast.second, this.expected_non_terminals[1])
if this.flat:
# flatten the AST if ast.first or ast.second have the same root operator tha the AST being built.
return ast
TODO: each parser should be passed a context to allow rewriting of bound identifiers on the AST being constructed. A special rewriting should be done for comprehension sets and alike, because the bound variables are not known before the parsing of the actual expression
- atomicParser
- inherits from NudParser. Its nudfunction implements something like (pseudocode):
nud(Symbol value):
ast = new AST(this.id, this.gid, value)
return ast
- postfixParser
- inherits from LedParser. Its ledfunction implements something like (pseudo-code):
led(AST left, Symbol value):
ast = new AST(this.id, this.gid, value)
ast.first = left
verify_expected_group(ast.first, this.expected_non_terminals[0])
if this.flat:
# flatten the AST if ast.first or ast.second have the same root operator tha the AST being built.
return ast
- prefixParser
- inherits from NudParser. Its nudfunction implements something like (pseudo-code):
nud(Symbol value):
ast = new AST(this.id, this.gid, value)
ast.first = this.subparsers[0].parse(ast, is_right_associative=False)
verify_expected_group(ast.first, this.expected_non_terminals[0])
if this.flat:
# flatten the AST if ast.first or ast.second have the same root operator tha the AST being built.
return ast
- functionalPostfixParser
- inherits from LedParser. It has a supplementary {ident|close_symbol}} attribute, and its ledfunction implements something like (pseudo-code):
led(AST left, Symbol value):
ast = new AST(this.id, this.gid, value)
ast.first = left
verify_expected_group(ast.first, this.expected_non_terminals[0])
ast.second = this.subparsers[0].parse(ast, is_right_associative=False)
# is_right_associative parameter should be set to True for a right associative infix parser
verify_expected_group(ast.second, this.expected_non_terminals[1])
this.tokenizer.advance(this.close_symbol) #consume the close symbol or raise a SyntaxError
return ast
Open Questions
How does the user specify the expected AST?
- Some examples in the existing parser:
- Bound identifiers are converted to de Bruijn indexes while constructing the AST. Is this desirable ? How does the user specify that identifier are bound or not ?
- In fact, the rewriting of bound identifier is done in the pre-existing parsers, so there is no need for the user to specify if an identifier will be bound or not. The user has just to select the parser he want to use (lambda like, set like, ...)
Sample Implementation
A prototype as been developed in Python to quickly try different solutions.
The development tree of the python prototype is available at http://bitbucket.org/matclab/eventb_pratt_parser/ with the default branch implementing a rather functional approach and the object branch being a first try to a more object based implementation.
Tests
- Regression tests. The tests of the existing parser shall succeed when applied to the generic parser.
- New tests.