Modus Ponens generalized
This page describe the design of a tactic replacing a predicate 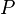 in either an hypothesis or a goal by
in either an hypothesis or a goal by 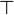 (respectively
(respectively 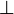 ) if (respectively
) if (respectively  ) is an hypothesis. That tactic is slightly different from the one requested : Feature Request #3137918
) is an hypothesis. That tactic is slightly different from the one requested : Feature Request #3137918
Objective
A sequent can be simplified by finding every occurrence of an hypothesis in the others hypothesis or goal, and replacing it by or as explained below:
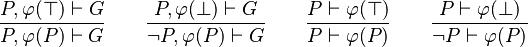
Contrary to the Feature Request, the rule is applied on every occurrence of and not only on the one appearing in a disjunctive form. Also, not to make explode the analyzing-time of a sequent, only goal and visible (or selected, it is still in discussion) hypothesis can be re-written, using every hypothesis (global and local). The analyzing-time performance of a sequent can be problematic since every predicate of goal and visible (or selected) hypothesis are checked. But it is still worthy because it may simplify a lot, and so make proof obligation more legible to humans.
Legacy
There already exist a reasoner that does a part of that tactic : autoImpF (ImpE automatic). It looks for implicative hypothesis in a sequent. Among the predicates computed by breaking possible conjunctions in the left side of the implication, it checks if some appear in selected hypothesis. In that case, every predicates which are hypothesis (global or local) are removed from the left-sided-predicate of the implication. If it remains no predicates, then the right side of the implication is re-written as a list of conjunction, else implication is re-written without the removed predicates (possibly none).
Then this reasoner can be considered as "intelligent" because it finds itself the positions where apply, which infer a code hard to read. On the contrary, as reasoners are in the trust-base, they should be easily understandable.
Modifications are provided to make it more legible.
Design Decision
The main drawback of this tactic is its execution time. Indeed, each (actually it is not the case but it helps to see how greedy this tactics can be) sub-predicate of each goal and visible (or selected) hypothesis is compared to the others hypothesis (global and local). Several strategies can be applied in order to reduce that execution-time :
- Each hypothesis must be scanned only once to avoid accumulating predicate's running time. From that point of view, two decisions can be inferred :
- A given predicate is compared once to every hypothesis. For instance, we do not try to find every occurrence of an hypothesis among the goal and the visible (or selected) hypothesis. In that case, each predicate would be scanned many times, accumulating execution time.
- That tactic apply the rules specified here-above everywhere it is possible. Thus, from this set of hypothesis :
- We will reach immediatly :
- Which will be re-written to :
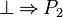
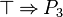
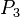
- Instead of writing :
- Re-written :
- And then :
- Re-written :
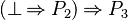
- When a predicate match an hypothesis, its children must not be analyzed.
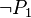
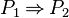
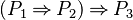
- In that example, the sub-predicate
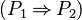 of the third predicate match to the second one. It has to be replaced by , and all its children have to be not analyzed (even if
of the third predicate match to the second one. It has to be replaced by , and all its children have to be not analyzed (even if 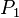 could have been replaced by because of the first predicate).
could have been replaced by because of the first predicate).
- In the case of n-ary predicates, each possibility is not tested.
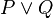
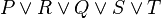
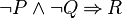
- In that example, could be replaced by in the second predicate. In order not to add more calculation time, this kind of replacement is not computed.
That reasoner can be considered as "intelligent", similarly to autoImpF because it computes by its own where it has to apply the rules.
Implementation
In this part is explained how the previous choices have been implemented with Java.
First, every hypothesis are stocked in a HashMap. The key is the hypothesis itself, its value is if the hypothesis is a negation, else. Because the HashMap provides a constant-time performance for the basic operations (get and put), it is very relevant for what we have to do (add hypothesis to it and recover it to compare with a predicate).
Then, we look first in the goal if one of the rule can be applied. If so, we record the goal itself as key in a new HashMap, as well as a List of all the positions were a rule can be applied. In the same HashMap, visible (or selected) hypothesis are record following the same procedure.
Once this job done, every sub-predicate recorded in the second HashMap (a predicate plus a position) is controlled as being (itself or its negation form) an hypothesis. Thus, it is ensured that the algorithm matching sub-predicate with an hypothesis did not mistake (control of the HashMap's work). If it's the case, replacement is proceeded.