Structured Types: Difference between revisions
imported>WikiSysop |
imported>Mathieu |
||
| (21 intermediate revisions by one other user not shown) | |||
| Line 4: | Line 4: | ||
Nevertheless it is possible to model structured types using projection functions to represent the fields/attributes. For example, | Nevertheless it is possible to model structured types using projection functions to represent the fields/attributes. For example, | ||
suppose we wish to model a record structure ''R'' with fields ''e'' and ''f'' (with type ''E'' and ''F'' respectively). | suppose we wish to model a record structure ''R'' with fields ''e'' and ''f'' (with type ''E'' and ''F'' respectively). | ||
Let us use the following 'invented' syntax for this (not part of Event-B syntax): | Let us use the following 'invented' syntax for this (based on VDM syntax but currently not part of Event-B syntax): | ||
<center> | <center> | ||
| Line 42: | Line 42: | ||
The approach to modelling structured types is based on a proposal by Evans and Butler | The approach to modelling structured types is based on a proposal by Evans and Butler | ||
[http://eprints.ecs.soton.ac.uk/12024/]. | [http://eprints.ecs.soton.ac.uk/12024/]. | ||
We refer to this approach to modelling records as a ''projection-based'' approach. | |||
Later we will look at a ''constructor-based'' approach and make the link between the two approaches. | |||
==Constructing Structured Values== | ==Constructing Structured Values== | ||
| Line 162: | Line 165: | ||
</math></center> | </math></center> | ||
This is a form of superposition refinement where we add more data structure to the state by | |||
adding a new field to elements of the structured type ''R''. In the above event we strengthen | |||
the specification by adding a guard using the event extension mechanism. | |||
The event extension mechanism means that this short form is the same as specifying | The event extension mechanism means that this short form is the same as specifying | ||
the refined event as follows: | the refined event as follows: | ||
| Line 185: | Line 191: | ||
Sometimes we wish to have different subtypes of a structure at the ''same'' abstraction level. | Sometimes we wish to have different subtypes of a structure at the ''same'' abstraction level. | ||
We can achieve this by defining | We can achieve this by defining subsets of the structure type and defining projection functions for those | ||
subsets only. For example suppose we define a message type that has sender and receiver fields as well | subsets only. For example suppose we define a message type that has ''sender'' and ''receiver'' fields as well | ||
as a message identifier. | as a message ''identifier''. | ||
In our invented notation this would be: | In our invented notation this would be: | ||
| Line 256: | Line 262: | ||
{{SimpleHeader}} | {{SimpleHeader}} | ||
|<math> \begin{array}{l} | |<math> \begin{array}{l} | ||
\textbf{CONSTANTS}~~ product,~ amount, price\\ | \textbf{CONSTANTS}~~ product,~ amount,~ price\\ | ||
\textbf{AXIOMS}\\ | \textbf{AXIOMS}\\ | ||
~~~~\begin{array}{l} | ~~~~\begin{array}{l} | ||
| Line 268: | Line 274: | ||
</center> | </center> | ||
Typically we would require that the message subtypes are disjoint. In that case we would add | Typically we would require that the message subtypes are disjoint. In that case we would add an additional axiom: | ||
<center> | <center> | ||
| Line 282: | Line 288: | ||
</center> | </center> | ||
If we know that | If we know that there are no other subtypes besides requests and confirmations and that they should be disjoint, | ||
then we can condense subset and disjointness axioms into a partitions axiom: | then we can condense the subset and disjointness axioms into a partitions axiom: | ||
<center> | <center> | ||
{{SimpleHeader}} | {{SimpleHeader}} | ||
| Line 310: | Line 316: | ||
The following ''Confirm'' event models an agent responding to request by issuing a confirmation message. | The following ''Confirm'' event models an agent responding to request by issuing a confirmation message. | ||
The | The ''Confirm'' event is enabled for the agent if there is a request message, ''req'', whose receiver is that agent. | ||
The effect of the event is to chose a confirmation message, ''conf'', whose fields are constrained with appropriate guards and | The effect of the event is to chose a confirmation message, ''conf'', whose fields are constrained with appropriate guards and add that confirmation message to the confirmations channel: | ||
<center><math> | <center><math> | ||
| Line 328: | Line 334: | ||
\end{array} | \end{array} | ||
</math></center> | </math></center> | ||
It might seem that we should always specify that subtypes are disjoint, but this is not so. | |||
Not making them disjoint allows us to represent a form of 'mulitple inheritance'. | |||
For example, we could declare a new subtype ''ReqConfMessage'' that subsets both | |||
''ReqMessage'' and ''ConfMessage'': | |||
<center> | |||
{{SimpleHeader}} | |||
|<math> \begin{array}{l} | |||
\textbf{CONSTANTS}~~ \textit{ReqConfMessage},\\ | |||
\textbf{AXIOMS}\\ | |||
~~~~\begin{array}{l} | |||
\textit{ReqConfMessage} \subseteq \textit{ReqMessage} \\ | |||
\textit{ReqConfMessage} \subseteq \textit{ConfMessage} \\ | |||
\end{array} | |||
\end{array} | |||
</math> | |||
|} | |||
</center> | |||
Elements of ''ReqConfMessage'' will have the fields of both subtypes, i.e., | |||
''sender'', ''receiver'', ''ident'', ''product'', ''amount'' and ''price''. | |||
This combined subtype could be further extended: | |||
<center> | |||
{{SimpleHeader}} | |||
|<math> \begin{array}{l} | |||
\textbf{EXTEND~~ RECORD}~~ \textit{ReqConfMessage}~~\textbf{WITH}\\ | |||
~~~~~~~~~~~~ time\in TIME\\ \end{array} | |||
</math> | |||
|} | |||
</center> | |||
For an example of a Rodin development that uses the projection-based approach to modelling and extending records see [http://deploy-eprints.ecs.soton.ac.uk/9/] | |||
==Constructor-based Records== | |||
An alternative style of modelling records is to define constructor functions that | |||
construct a record from a tuple of the components of that record. | |||
This is the approach that VDM follows, for example. | |||
Suppose we wish to model the following record structure: | |||
<center> | |||
{{SimpleHeader}} | |||
|<math> \begin{array}{lcl} | |||
\textbf{RECORD}~~~~ R &::& e\in E\\ | |||
&& f \in F | |||
\end{array} | |||
</math> | |||
|} | |||
</center> | |||
We introduce the constructor function for ''R'' records, ''mk-R'', as follows: | |||
<center> | |||
{{SimpleHeader}} | |||
|<math> \begin{array}{l} | |||
\textbf{SETS}~~ R\\ | |||
\textbf{CONSTANTS}~~ \textit{mk-R},~ e,~ f\\ | |||
\textbf{AXIOMS}\\ | |||
~~~~\begin{array}{l} | |||
\textit{mk-R} ~\in~ (E\times F) \tbij R\\ | |||
e \in R \tfun E\\ | |||
f \in R \tfun F\\ | |||
\forall x,y \cdot e( \textit{mk-R}(x\mapsto y) ) = x \\ | |||
\forall x,y \cdot f( \textit{mk-R}(x\mapsto y) ) = y | |||
\end{array} | |||
\end{array} | |||
</math> | |||
|} | |||
</center> | |||
The ''mk-R'' function is specified as a constructor for type ''R'' that takes an element of type ''E'' and an element of type ''F'' | |||
and constructs an value of type ''R''. | |||
The constructor is specified as injective because when the components are different, then the corresponding records should be different. | |||
The above declaration also makes the constructor surjective which means that the constructor provides a way of generating all | |||
records of type ''R''. | |||
With the constructor based approach, the ''AddElement'' event already shown above does not require a selection of a | |||
record satisfying the required properties. Instead we use the constructor directly: | |||
<center><math> | |||
AddElement ~= | |||
\begin{array}[t]{l} | |||
\textbf{BEGIN}\\ | |||
~~~~ vs := vs \cup \{~ \textit{mk-R}(e1,f1) ~\} \\ | |||
\textbf{END} | |||
\end{array} | |||
</math></center> | |||
It is possible to define different subtypes in a similar way as in the projection-based approach by defining separate constructors for | |||
each (disjoint) subtype. | |||
Adding new fields in a refinement is more difficult with the constructor approach however. | |||
We would need to introduce a completely new constructor for the full extended record structure and | |||
to get the refinement to work correctly, we would need to define a relationship between the original | |||
record and the extended version. This merits further exploration. | |||
==Projections versus Constructors== | |||
As we have seen, the constructor approach can lead to more succinct event specifications | |||
than the projection approach. | |||
The downside of the constructor approach is that it is difficult to extend records in refinement steps and | |||
stepwise refinement and introduction of structure through refinement is an major feature of the | |||
Event-B approach. | |||
We could say that the projection approach gives us ''open'' record structures, that is, | |||
structures that are easy to extend in a refinement. The constructor approach gives us | |||
''closed'' records that are not directly extendable in refinement steps. | |||
The constructor approach can be seen as a strengtening of the projection approach | |||
as is now explained. Consider again the two projection functions introduced to | |||
represent fields of the record structure ''R'' in the projection approach: | |||
<center> | |||
{{SimpleHeader}} | |||
|<math> \begin{array}{l} | |||
\textbf{AXIOMS}\\ | |||
~~~~\begin{array}{l} | |||
e \in R \tfun E\\ | |||
f \in R \tfun F | |||
\end{array} | |||
\end{array} | |||
</math> | |||
|} | |||
</center> | |||
The direct product of these two projections <math>(e \otimes f)</math> has the following type: | |||
<center> | |||
{{SimpleHeader}} | |||
|<math> \begin{array}{l} | |||
~~~~\begin{array}{l} | |||
e \otimes f ~\in~ R \tfun (E\times F) | |||
\end{array} | |||
\end{array} | |||
</math> | |||
|} | |||
</center> | |||
The inverse of the direct product | |||
<math>(e \otimes f)^{-1}</math> relates pairs of type <math>E\times F</math> to elements of type <math>R</math>. | |||
If we specify that <math>e \otimes f</math> is injective, i.e., its inverse is a function, then <math>(e \otimes f)^{-1}</math> | |||
becomes a constructor function for records of type <math>R</math>. | |||
This means that an open record structure can be 'closed-off' by the addition of an axiom stating that | |||
the direct product of the fields is injective: | |||
<center> | |||
{{SimpleHeader}} | |||
|<math> \begin{array}{l} | |||
\textbf{AXIOMS}~~~~~~\textit{ (Closing) }\\ | |||
~~~~\begin{array}{l} | |||
e \otimes f ~\in~ R \tinj (E\times F) | |||
\end{array} | |||
\end{array} | |||
</math> | |||
|} | |||
</center> | |||
Once this ''closing'' axiom is introduced, we can no longer introduce new fields to the record structure - at least | |||
not without introducing an inconsistency. If we were to now add a field ''g'', the closing axiom would mean | |||
that records whose ''e'' and ''f'' fields are the same, must be correspond to the same record ''r'' even if they differ | |||
in the ''g'' field. But since ''g'' is a function, different ''g'' values cannot be related to the same record ''r''. | |||
Regardless of whether the closing axiom is introduced, some feasibility proof obligations arising from the use of the | |||
projection approach will require the existence of a record corresponding to any tuple of field components. This can be | |||
specified by the following ''feasibility'' axiom stating that the product of the projections is surjective: | |||
<center> | |||
{{SimpleHeader}} | |||
|<math> \begin{array}{l} | |||
\textbf{AXIOMS}~~~~~~\textit{ (Feasibility) }\\ | |||
~~~~\begin{array}{l} | |||
e \otimes f ~\in~ R \tsur (E\times F) | |||
\end{array} | |||
\end{array} | |||
</math> | |||
|} | |||
</center> | |||
==Recursive Structured Types== | ==Recursive Structured Types== | ||
It is well known how to deal with recursive records using the constructor approach. | |||
This is explored further in the context of Event-B and Rodin as part of the mathematical extension | |||
work where proposals for inductive datatypes are made (see [[Mathematical_extensions]]). | |||
Inductive datatypes are defined by constructor functions similar to constructor-based records. | |||
For example, to define lists we would use two disjoint constructors, ''nil'' and ''cons''. | |||
The ''cons'' constructor for lists typically comes with two projections, ''head'' and ''tail''. | |||
The structural induction principle for inductive datatypes is well known. | |||
With the projection approach we can define two subtypes, for empty and non-empty lists, | |||
and extend the non-empty subtype with ''head'' and ''tail'' projections. | |||
<center> | |||
{{SimpleHeader}} | |||
|<math> \begin{array}{l} | |||
\textbf{SETS}~~ T,~ Node\\ | |||
\textbf{CONSTANTS}~~ Nil,~ Cons\\ | |||
\textbf{AXIOMS}\\ | |||
~~~~\begin{array}{l} | |||
partition(~ Node, ~Nil,~ Cons ~) | |||
\end{array} \\~\\ | |||
\textbf{EXTEND~~ RECORD}~~ \textit{Cons}~~\textbf{WITH}\\ | |||
~~~~~~~~~~~~ head\in T \\ | |||
~~~~~~~~~~~~ tail\in LIST | |||
\end{array} | |||
</math> | |||
|} | |||
</center> | |||
The appropriate induction principle for the projection based approach needs to be explored further. | |||
==Structured Variables== | ==Structured Variables== | ||
To be done... | |||
[[Category:Work in progress]] [[Category:Design]] | |||
Latest revision as of 12:41, 12 August 2009
Modelling Structured Types
The Event-B mathematical language currently does not support a syntax for the direct definition of structured types such as records or class structures. Nevertheless it is possible to model structured types using projection functions to represent the fields/attributes. For example, suppose we wish to model a record structure R with fields e and f (with type E and F respectively). Let us use the following 'invented' syntax for this (based on VDM syntax but currently not part of Event-B syntax):
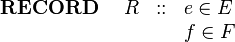
|
We can model this structure in Event-B by introducing (in a context) a carrier set R and two functions e and f as constants as follows:
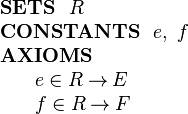
|
The (constant) functions e and f are projection functions that can be used to extract the appropriate field values.
That is, given an element 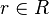 representing a record structure, we write
representing a record structure, we write 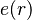 for the e component of r and
for the e component of r and 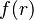 for the f component of r.
for the f component of r.
E and F can be any type definable in Event-B, including a type representing a record structure.
The approach to modelling structured types is based on a proposal by Evans and Butler [1]. We refer to this approach to modelling records as a projection-based approach. Later we will look at a constructor-based approach and make the link between the two approaches.
Constructing Structured Values
Suppose we have a variable v in a machine whose type is the structure R defined above:
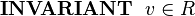
We wish to assign a structured value to v whose e field has some value e1 and whose f field has some value f1. This can be achieved by specifying the choice of an event parameter r whose fields are constrained by appropriate guards and assigning parameter r to the machine variable v. This is shown in the following event:
![Ev1 ~=\begin{array}[t]{l}
\textbf{ANY}~~ r ~~\textbf{WHERE} \\
~~~~ r \in R \\
~~~~ e( r ) = e1 \\
~~~~ f( r ) = f1 \\
\textbf{THEN} \\
~~~~ v := r \\
\textbf{END}
\end{array}](/images/math/c/0/a/c0acb8ea42c896a857cb486bf58e89c5.png)
If we only wish to update some fields and leave others changed, this needs to be done by specifying explicitly that some fields remain unchanged. This is shown in the following example where only the e field is modified:
![Ev2 ~=\begin{array}[t]{l}
\textbf{ANY}~~ r ~~\textbf{WHERE} \\
~~~~ r \in R \\
~~~~ e( r ) = e1 \\
~~~~ f( r ) = f(v) \\
\textbf{THEN} \\
~~~~ v := r \\
\textbf{END}
\end{array}](/images/math/b/4/b/b4b0c62e8c2f0b200e0b603baffe0232.png)
If we don't care about the value of some field (e.g., f), we simply omit any guard on that field as follows:
![Ev3 ~= \begin{array}[t]{l}
\textbf{ANY}~~ r ~~\textbf{WHERE} \\
~~~~ r \in R \\
~~~~ e( r ) = e1 \\
\textbf{THEN} \\
~~~~ v := r \\
\textbf{END}
\end{array}](/images/math/1/6/0/16084255bc2a039f74d290d8f445e8ed.png)
Sometimes we will wish to model a set of structured elements as a machine variable, e.g.,
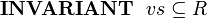
We can add a structured element to this set using the following event:
![AddElement ~=
\begin{array}[t]{l}
\textbf{ANY}~~ r ~~\textbf{WHERE} \\
~~~~ r \in R \\
~~~~ e( r ) = e1 \\
~~~~ f( r ) = f1 \\
\textbf{THEN} \\
~~~~ vs := vs \cup \{r\} \\
\textbf{END}
\end{array}](/images/math/8/9/5/895f1186bc2e29ebdcac258ad8b929b1.png)
Extending Structured Types
In a refinement we can introduce new fields to an existing structured type. Suppose R is defined in context C1 with fields e and f as before. For the refinement, suppose we wish to add a field g of type G to structured type R. Let us use the following invented syntax for this (not part of Event-B syntax):
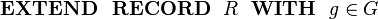
|
This can be done by including the new field g as projection function on R in a context C2 (that extends C1). The new field is defined as follows:
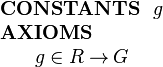
|
Above, we saw the AddElement event that adds a structured element to the set vs. We may want to specify a value for the new g field in the refinement of this event. Using the event extension mechanism, this can be achieved as follows:
![AddElement~= \begin{array}[t]{l}
\textbf{EXTENDS}~~ AddElement \\
\textbf{WHEN} \\
~~~~ g( r ) = g1 \\
\textbf{THEN} \\
~~~~ skip \\
\textbf{END}
\end{array}](/images/math/e/c/4/ec4898896eebca6d817c466fcd201b9b.png)
This is a form of superposition refinement where we add more data structure to the state by adding a new field to elements of the structured type R. In the above event we strengthen the specification by adding a guard using the event extension mechanism. The event extension mechanism means that this short form is the same as specifying the refined event as follows:
![AddElement ~=
\begin{array}[t]{l}
\textbf{REFINES}~~ AddElement \\
\textbf{ANY}~~ r ~~\textbf{WHERE} \\
~~~~ r \in R \\
~~~~ e( r ) = e1 \\
~~~~ f( r ) = f1 \\
~~~~ g( r ) = g1 \\
\textbf{THEN} \\
~~~~ vs := vs \cup \{r\} \\
\textbf{END}
\end{array}](/images/math/a/0/2/a02af36631152aeb174233bd77b56b58.png)
Sub-Typing
Extension, as described above, is used when adding new fields to a structured type as part of a refinement step. That is, at different abstraction levels, we may have different numbers of fields in a structured type.
Sometimes we wish to have different subtypes of a structure at the same abstraction level. We can achieve this by defining subsets of the structure type and defining projection functions for those subsets only. For example suppose we define a message type that has sender and receiver fields as well as a message identifier. In our invented notation this would be:
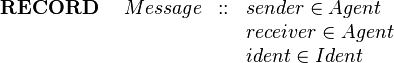
|
In Event-B this would be:

|
We wish to have two subtypes of message, request messages and confirmation messages. We define two subsets of Message as follows:
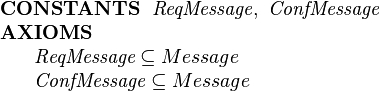
|
We require requests to have a product and an amount field and a confirmation to have a price field.
In our invented notation this would be specified as follows:

|
In Event-B the additional fields are specified as projection functions on the relevant message subsets:

|
Typically we would require that the message subtypes are disjoint. In that case we would add an additional axiom:
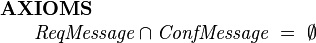
|
If we know that there are no other subtypes besides requests and confirmations and that they should be disjoint, then we can condense the subset and disjointness axioms into a partitions axiom:
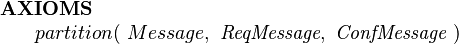
|
Suppose we have 2 variables representing request and confirmation channels repsectively:
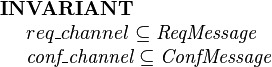
The following Confirm event models an agent responding to request by issuing a confirmation message. The Confirm event is enabled for the agent if there is a request message, req, whose receiver is that agent. The effect of the event is to chose a confirmation message, conf, whose fields are constrained with appropriate guards and add that confirmation message to the confirmations channel:
![Confirm ~=
\begin{array}[t]{l}
\textbf{ANY}~~ req,~ conf, ~ agent ~~\textbf{WHERE} \\
~~~~ req \in req\_channel \\
~~~~ agent = receiver(req) \\
~~~~ conf \in \textit{ConfMessage} \\
~~~~ sender( conf ) = agent \\
~~~~ receiver( conf ) = sender(req) \\
~~~~ price(conf) = calculate\_price(~ product(req)\mapsto amount(req) ~) \\
\textbf{THEN} \\
~~~~ \textit{conf\_channel} := \textit{conf\_channel} \cup \{conf\} \\
\textbf{END}
\end{array}](/images/math/8/4/a/84acead8133f80a009ccb8a3e3bdd837.png)
It might seem that we should always specify that subtypes are disjoint, but this is not so.
Not making them disjoint allows us to represent a form of 'mulitple inheritance'.
For example, we could declare a new subtype ReqConfMessage that subsets both
ReqMessage and ConfMessage:
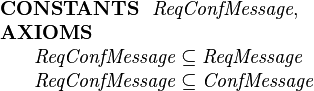
|
Elements of ReqConfMessage will have the fields of both subtypes, i.e., sender, receiver, ident, product, amount and price.
This combined subtype could be further extended:
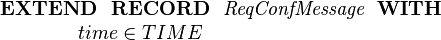
|
For an example of a Rodin development that uses the projection-based approach to modelling and extending records see [2]
Constructor-based Records
An alternative style of modelling records is to define constructor functions that construct a record from a tuple of the components of that record. This is the approach that VDM follows, for example. Suppose we wish to model the following record structure:
|
|
We introduce the constructor function for R records, mk-R, as follows:
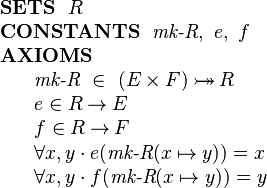
|
The mk-R function is specified as a constructor for type R that takes an element of type E and an element of type F and constructs an value of type R. The constructor is specified as injective because when the components are different, then the corresponding records should be different. The above declaration also makes the constructor surjective which means that the constructor provides a way of generating all records of type R.
With the constructor based approach, the AddElement event already shown above does not require a selection of a record satisfying the required properties. Instead we use the constructor directly:
![AddElement ~=
\begin{array}[t]{l}
\textbf{BEGIN}\\
~~~~ vs := vs \cup \{~ \textit{mk-R}(e1,f1) ~\} \\
\textbf{END}
\end{array}](/images/math/3/2/e/32e2f153b6932886dae639e5fc342873.png)
It is possible to define different subtypes in a similar way as in the projection-based approach by defining separate constructors for each (disjoint) subtype.
Adding new fields in a refinement is more difficult with the constructor approach however. We would need to introduce a completely new constructor for the full extended record structure and to get the refinement to work correctly, we would need to define a relationship between the original record and the extended version. This merits further exploration.
Projections versus Constructors
As we have seen, the constructor approach can lead to more succinct event specifications than the projection approach. The downside of the constructor approach is that it is difficult to extend records in refinement steps and stepwise refinement and introduction of structure through refinement is an major feature of the Event-B approach.
We could say that the projection approach gives us open record structures, that is, structures that are easy to extend in a refinement. The constructor approach gives us closed records that are not directly extendable in refinement steps.
The constructor approach can be seen as a strengtening of the projection approach as is now explained. Consider again the two projection functions introduced to represent fields of the record structure R in the projection approach:
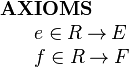
|
The direct product of these two projections 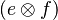 has the following type:
has the following type:
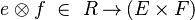
|
The inverse of the direct product
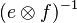 relates pairs of type
relates pairs of type 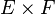 to elements of type
to elements of type 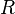 .
If we specify that
.
If we specify that 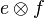 is injective, i.e., its inverse is a function, then
becomes a constructor function for records of type .
is injective, i.e., its inverse is a function, then
becomes a constructor function for records of type .
This means that an open record structure can be 'closed-off' by the addition of an axiom stating that the direct product of the fields is injective:
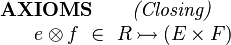
|
Once this closing axiom is introduced, we can no longer introduce new fields to the record structure - at least not without introducing an inconsistency. If we were to now add a field g, the closing axiom would mean that records whose e and f fields are the same, must be correspond to the same record r even if they differ in the g field. But since g is a function, different g values cannot be related to the same record r.
Regardless of whether the closing axiom is introduced, some feasibility proof obligations arising from the use of the projection approach will require the existence of a record corresponding to any tuple of field components. This can be specified by the following feasibility axiom stating that the product of the projections is surjective:
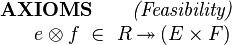
|
Recursive Structured Types
It is well known how to deal with recursive records using the constructor approach. This is explored further in the context of Event-B and Rodin as part of the mathematical extension work where proposals for inductive datatypes are made (see Mathematical_extensions). Inductive datatypes are defined by constructor functions similar to constructor-based records. For example, to define lists we would use two disjoint constructors, nil and cons. The cons constructor for lists typically comes with two projections, head and tail. The structural induction principle for inductive datatypes is well known.
With the projection approach we can define two subtypes, for empty and non-empty lists, and extend the non-empty subtype with head and tail projections.

|
The appropriate induction principle for the projection based approach needs to be explored further.
Structured Variables
To be done...